



]

It’s a few hours’ drive south in Santa Barbara, in a flat, soulless office park inhabited mostly by technology firms you’ve never heard of.
An open-plan office holds several dozen desks. There’s an indoor bicycle rack and designated “surfboard parking,” with boards resting on brackets that jut out from the wall. Wide double doors lead into a lab the size of a large classroom. There, amidst computer racks and jumbles of instrumentation, a handful of cylindrical vessels—each a little bigger than an oil drum—hang from vibration-damping rigs like enormous steel pupae.
On one of them, the outer vessel has been removed to expose a multi-tiered tangle of steel and brass innards known as “the chandelier.” It’s basically a supercharged refrigerator that gets colder with each layer down. At the bottom, kept in a vacuum a hair’s breadth above absolute zero, is what looks to the naked eye like an ordinary silicon chip. But rather than transistors, it’s etched with tiny superconducting circuits that, at these low temperatures, behave as if they were single atoms obeying the laws of quantum physics. Each one is a quantum bit, or qubit—the basic information–storage unit of a quantum computer.
Late last October, Google announced that one of those chips, called Sycamore, had become the first to demonstrate “quantum supremacy” by performing a task that would be practically impossible on a classical machine. With just 53 qubits, Sycamore had completed a calculation in a few minutes that, according to Google, would have taken the world’s most powerful existing supercomputer, Summit, 10,000 years. Google touted this as a major breakthrough, comparing it to the launch of Sputnik or the first flight by the Wright brothers—the threshold of a new era of machines that would make today’s mightiest computer look like an abacus.
At a press conference in the lab in Santa Barbara, the Google team cheerfully fielded questions from journalists for nearly three hours. But their good humor couldn’t quite mask an underlying tension. Two days earlier, researchers from IBM, Google’s leading rival in quantum computing, had torpedoed its big reveal. They’d published a paper that essentially accused the Googlers of getting their sums wrong. IBM reckoned it would have taken Summit merely days, not millennia, to replicate what Sycamore had done. When asked what he thought of IBM’s result, Hartmut Neven, the head of the Google team, pointedly avoided giving a direct answer.
You could dismiss this as just an academic spat—and in a sense it was. Even if IBM was right, Sycamore had still done the calculation a thousand times faster than Summit would have. And it would likely be only months before Google built a slightly larger quantum machine that proved the point beyond doubt.
IBM’s deeper objection, though, was not that Google’s experiment was less successful than claimed, but that it was a meaningless test in the first place. Unlike most of the quantum computing world, IBM doesn’t think “quantum supremacy” is the technology’s Wright brothers moment; in fact, it doesn’t even believe there will be such a moment.
IBM is instead chasing a very different measure of success, something it calls “quantum advantage.” This isn’t a mere difference of words or even of science, but a philosophical stance with roots in IBM’s history, culture, and ambitions—and, perhaps, the fact that for eight years its revenue and profit have been in almost unremitting decline, while Google and its parent company Alphabet have only seen their numbers grow. This context, and these differing goals, could influence which—if either—comes out ahead in the quantum computing race.
Worlds apart
The sleek, sweeping curve of IBM’s Thomas J. Watson Research Center in the suburbs north of New York City, a neo-futurist masterpiece by the Finnish architect Eero Saarinen, is a continent and a universe away from the Google team’s nondescript digs. Completed in 1961 with the bonanza IBM made from mainframes, it has a museum-like quality, a reminder to everyone who works inside it of the company’s breakthroughs in everything from fractal geometry to superconductors to artificial intelligence—and quantum computing.
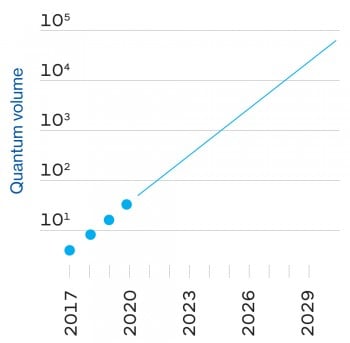
The head of the 4,000-strong research division is Dario Gil, a Spaniard whose rapid-fire speech races to keep up with his almost evangelical zeal. Both times I spoke to him, he rattled off historical milestones intended to underscore how long IBM has been involved in quantum-computing-related research (see time line at right).


A grand experiment: Quantum theory and practice
A quantum computer’s basic building block is the quantum bit, or qubit. In a classical computer, a bit can store either a 0 or a 1. A qubit can store not only 0 or 1 but also an in-between state called a superposition—which can assume lots of different values. One analogy is that if information were color, then a classical bit could be either black or white. A qubit when it’s in superposition could be any color on the spectrum, and could also vary in brightness.
The upshot is that a qubit can store and process a vast quantity of information compared with a bit—and capacity increases exponentially as you connect qubits together. Storing all the information in the 53 qubits on Google’s Sycamore chip would take about 72 petabytes (72 billion gigabytes) of classical computer memory. It doesn’t take a lot more qubits before you’d need a classical computer the size of the planet.
But it’s not straightforward. Delicate and easily disturbed, qubits need to be almost perfectly isolated from heat, vibration, and stray atoms—hence the “chandelier” refrigerators in Google’s quantum lab. Even then, they can function for at most a few hundred microseconds before they “decohere” and lose their superposition.
And quantum computers aren’t always faster than classical ones. They’re just different, faster at some things and slower at others, and require different kinds of software. To compare their performance, you have to write a classical program that approximately simulates the quantum one.
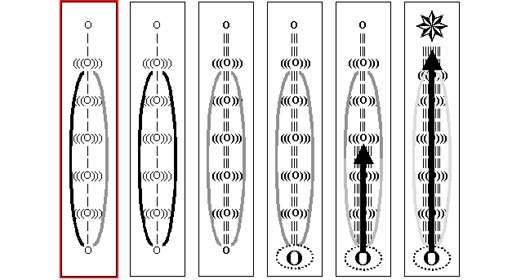
For its experiment, Google chose a benchmarking test called “random quantum circuit sampling.” It generates millions of random numbers, but with slight statistical biases that are a hallmark of the quantum algorithm. If Sycamore were a pocket calculator, it would be the equivalent of pressing buttons at random and checking that the display showed the expected results.
Google simulated parts of this on its own massive server farms as well as on Summit, the world’s biggest supercomputer, at Oak Ridge National Laboratory. The researchers estimated that completing the whole job, which took Sycamore 200 seconds, would have taken Summit approximately 10,000 years. Voilà: quantum supremacy.
So what was IBM’s objection? Basically, that there are different ways to get a classical computer to simulate a quantum machine—and that the software you write, the way you chop up data and store it, and the hardware you use all make a big difference in how fast the simulation can run. IBM said Google assumed the simulation would need to be cut up into a lot of chunks, but Summit, with 280 petabytes of storage, is big enough to hold the complete state of Sycamore at once. (And IBM built Summit, so it should know.)
But over the decades, the company has gained a reputation for struggling to turn its research projects into commercial successes. Take, most recently, Watson, the Jeopardy!-playing AI that IBM tried to convert into a robot medical guru. It was meant to provide diagnoses and identify trends in oceans of medical data, but despite dozens of partnerships with health-care providers, there have been few commercial applications, and even the ones that did emerge have yielded mixed results.
The quantum computing team, in Gil’s telling, is trying to break that cycle by doing the research and business development in parallel. Almost as soon as it had working quantum computers, it started making them accessible to outsiders by putting them on the cloud, where they can be programmed by means of a simple drag-and-drop interface that works in a web browser. The “IBM Q Experience,” launched in 2016, now consists of 15 publicly available quantum computers ranging from five to 53 qubits in size. Some 12,000 people a month use them, ranging from academic researchers to school kids. Time on the smaller machines is free; IBM says it already has more than 100 clients paying (it won’t say how much) to use the bigger ones.
None of these devices—or any other quantum computer in the world, except for Google’s Sycamore—has yet shown it can beat a classical machine at anything. To IBM, that isn’t the point right now. Making the machines available online lets the company learn what future clients might need from them and allows outside software developers to learn how to write code for them. That, in turn, contributes to their development, making subsequent quantum computers better.
This cycle, the company believes, is the fastest route to its so-called quantum advantage, a future in which quantum computers won’t necessarily leave classical ones in the dust but will do some useful things somewhat faster or more efficiently—enough to make them economically worthwhile. Whereas quantum supremacy is a single milestone, quantum advantage is a “continuum,” the IBMers say—a gradually expanding world of possibility.
This, then, is Gil’s grand unified theory of IBM: that by combining its heritage, its technical expertise, other people’s brainpower, and its dedication to business clients, it can build useful quantum computers sooner and better than anybody else.
In this view of things, IBM sees Google’s quantum supremacy demonstration as “a parlor trick,” says Scott Aaronson, a physicist at the University of Texas at Austin, who contributed to the quantum algorithms Google is using. At best it’s a flashy distraction from the real work that needs to take place. At worst it’s misleading, because it could make people think quantum computers can beat classical ones at anything rather than at one very narrow task. “‘Supremacy’ is an English word that it’s going to be impossible for the public not to misinterpret,” says Gil.
Google, of course, sees it rather differently.
Enter the upstart
Google was a precocious eight-year-old company when it first began tinkering with quantum problems in 2006, but it didn’t form a dedicated quantum lab until 2012—the same year John Preskill, a physicist at Caltech, coined the term “quantum supremacy.”
The head of the lab is Hartmut Neven, a German computer scientist with a commanding presence and a penchant for Burning Man–style chic; I saw him once in a furry blue coat and another time in an all-silver outfit that made him look like a grungy astronaut. (“My wife buys these things for me,” he explained.) Initially, Neven bought a machine built by an outside firm, D-Wave, and spent a while trying to achieve quantum supremacy on it, but without success. He says he convinced Larry Page, Google’s then CEO, to invest in building quantum computers in 2014 by promising him that Google would take on Preskill’s challenge: “We told him, ‘Listen, Larry, in three years we will come back and put a prototype chip on your table that can at least compute a problem that is beyond the abilities of classical machines.’”
Lacking IBM’s quantum expertise, Google hired a team from outside, led by John Martinis, a physicist at the University of California, Santa Barbara. Martinis and his group were already among the world’s best quantum computer makers—they had managed to string up to nine qubits together—and Neven’s promise to Page seemed like a worthy goal for them to aim for.
The three-year deadline came and went as Martinis’s team struggled to make a chip both big enough and stable enough for the challenge. In 2018 Google released its largest processor yet, Bristlecone. With 72 qubits, it was well ahead of anything its rivals had made, and Martinis predicted it would attain quantum supremacy that same year. But a few of the team members had been working in parallel on a different chip architecture, called Sycamore, that ultimately proved able to do more with fewer qubits. Hence it was a 53-qubit chip—originally 54, but one of them malfunctioned—that ultimately demonstrated supremacy last fall.
For practical purposes, the program used in that demonstration is virtually useless—it generates random numbers, which isn’t something you need a quantum computer for. But it generates them in a particular way that a classical computer would find very hard to replicate, thereby establishing the proof of concept (see opposite page).
Ask IBMers what they think of this achievement, and you get pained looks. “I don’t like the word [supremacy], and I don’t like the implications,” says Jay Gambetta, a cautiously spoken Australian who heads IBM’s quantum team. The problem, he says, is that it’s virtually impossible to predict whether any given quantum calculation will be hard for a classical machine, so showing it in one case doesn’t help you find other cases.
To everyone I spoke with outside IBM, this refusal to treat quantum supremacy as significant verges on pigheadedness. “Anybody who will ever have a commercially relevant offering—they have to show supremacy first. I think that’s just basic logic,” says Neven. Even Will Oliver, a mild-mannered MIT physicist who has been one of the most even-handed observers of the spat, says, “It’s a very important milestone to show a quantum computer outperforming a classical computer at some task, whatever it is.”
The quantum leap
Regardless of whether you agree with Google’s position or IBM’s, the next goal is clear, Oliver says: to build a quantum computer that can do something useful. The hope is that such machines could one day solve problems that require unfeasible amounts of brute-force computing power now, like modeling complex molecules to help discover new drugs and materials, or optimizing city traffic flows in real time to reduce congestion, or making longer-term weather predictions. (Eventually they might be capable of cracking the cryptographic codes used today to secure communications and financial transactions, though by then most of the world will probably have adopted quantum-resistant cryptography.) The trouble is that it’s nearly impossible to predict what the first useful task will be, or how big a computer will be needed to perform it.
That uncertainty has to do with both hardware and software. On the hardware side, Google reckons its current chip designs can get it to somewhere between 100 and 1,000 qubits. However, just as a car’s performance doesn’t depend only on the size of the engine, a quantum computer’s performance isn’t simply determined by its number of qubits. There is a raft of other factors to take into account, including how long they can be kept from decohering, how error-prone they are, how fast they operate, and how they’re interconnected. This means any quantum computer operating today reaches only a fraction of its full potential.
Software for quantum computers, meanwhile, is as much in its infancy as the machines themselves. In classical computing, programming languages are now several levels removed from the raw “machine code” that early software developers had to use, because the nitty-gritty of how data get stored, processed, and shunted around is already standardized. “On a classical computer, when you program it, you don’t have to know how a transistor works,” says Dave Bacon, who leads the Google team’s software effort. Quantum code, on the other hand, has to be highly tailored to the qubits it will run on, so as to wring the most out of their temperamental performance. That means the code for IBM’s chips won’t run on those of other companies, and even techniques for optimizing Google’s 53-qubit Sycamore won’t necessarily do well on its future 100-qubit sibling. More important, it means nobody can predict just how hard a problem those 100 qubits will be capable of tackling.
The most anyone dares to hope for is that computers with a few hundred qubits will be cajoled into simulating some moderately complex chemistry within the next few years—perhaps even enough to advance the search for a new drug or a more efficient battery. Yet decoherence and errors will bring all these machines to a stop before they can do anything really hard like breaking cryptography.
That will require a “fault-tolerant” quantum computer, one that can compensate for errors and keep itself running indefinitely, just as classical ones do. The expected solution will be to create redundancy: make hundreds of qubits act as one, in a shared quantum state. Collectively, they can correct for individual qubits’ errors. And as each qubit succumbs to decoherence, its neighbors will bring it back to life, in a never–ending cycle of mutual resuscitation.
The typical prediction is that it would take as many as 1,000 conjoined qubits to attain that stability—meaning that to build a computer with the power of 1,000 qubits, you’d need a million actual ones. Google “conservatively” estimates it can build a million-qubit processor within 10 years, Neven says, though there are some big technical hurdles to overcome, including one in which IBM may yet have the edge over Google (see opposite page).
By that time, a lot may have changed. The superconducting qubits Google and IBM currently use might prove to be the vacuum tubes of their era, replaced by something much more stable and reliable. Researchers around the world are experimenting with various methods of making qubits, though few are advanced enough to build working computers with. Rival startups such as Rigetti, IonQ, or Quantum Circuits might develop an edge in a particular technique and leapfrog the bigger companies.
A tale of two transmons
Google’s and IBM’s transmon qubits are almost identical, with one small but potentially crucial difference.
In both Google’s and IBM’s quantum computers, the qubits themselves are controlled by microwave pulses. Tiny fabrication defects mean that no two qubits respond to pulses of exactly the same frequency. There are two solutions to this: vary the frequency of the pulses to find each qubit’s sweet spot, like jiggling a badly cut key in a lock until it opens; or use magnetic fields to “tune” each qubit to the right frequency.
IBM uses the first method; Google uses the second. Each approach has pluses and minuses. Google’s tunable qubits work faster and more precisely, but they’re less stable and require more circuitry. IBM’s fixed-frequency qubits are more stable and simpler, but run more slowly.
From a technical point of view, it’s pretty much a toss-up, at least at this stage. In terms of corporate philosophy, though, it’s the difference between Google and IBM in a nutshell—or rather, in a qubit.
Google chose to be nimble. “In general our philosophy goes a little bit more to higher controllability at the expense of the numbers that people typically look for,” says Hartmut Neven.
IBM, on the other hand, chose reliability. “There’s a huge difference between doing a laboratory experiment and publishing a paper, and putting a system up with, like, 98% reliability where you can run it all the time,” says Dario Gil.
Right now, Google has the edge. As machines get bigger, though, the advantage may flip to IBM. Each qubit is controlled by its own individual wires; a tunable qubit requires one extra wire. Figuring out the wiring for thousands or millions of qubits will be one of the toughest technical challenges the two companies face; IBM says it’s one of the reasons they went with the fixed-frequency qubit. Martinis, the head of the Google team, says he’s personally spent the past three years trying to find wiring solutions. “It’s such an important problem that I worked on it,” he jokes.
But given their size and wealth, both Google and IBM have a shot at becoming serious players in the quantum computing business. Companies will rent their machines to tackle problems the way they currently rent cloud-based data storage and processing power from Amazon, Google, IBM, or Microsoft. And what started as a battle between physicists and computer scientists will evolve into a contest between business services divisions and marketing departments.
Which company is best placed to win that contest? IBM, with its declining revenues, may have a greater sense of urgency than Google. It knows from bitter experience the costs of being slow to enter a market: last summer, in its most expensive purchase ever, it forked over $34 billion for Red Hat, an open-source cloud services provider, in an attempt to catch up to Amazon and Microsoft in that field and reverse its financial fortunes. Its strategy of putting its quantum machines on the cloud and building a paying business from the get-go seems designed to give it a head start.
Google recently began to follow IBM’s example, and its commercial clients now include the US Department of Energy, Volkswagen, and Daimler. The reason it didn’t do this sooner, says Martinis, is simple: “We didn’t have the resources to put it on the cloud.” But that’s another way of saying it had the luxury of not having to make business development a priority.
Whether that decision gives IBM an edge is too early to say, but probably more important will be how the two companies apply their other strengths to the problem in the coming years. IBM, says Gil, will benefit from its “full stack” expertise in everything from materials science and chip fabrication to serving big corporate clients. Google, on the other hand, can boast a Silicon Valley–style culture of innovation and plenty of practice at rapidly scaling up operations.
As for quantum supremacy itself, it will be an important moment in history, but that doesn’t mean it will be a decisive one. After all, everyone knows about the Wright brothers’ first flight, but can anybody remember what they did afterwards?
Source: Technology Review